
Think tanks have the two assets that are the most prized by SEOs: valuable original content and high-quality links. Yet many fail to turn these assets into appreciable traffic.
For example, a think tank in our rankings has nearly 400,000 backlinks from over 11,000 domains yet only generates 28,000 clicks from search a month. This is a tiny sum compared to what similar stats would garner the typical publisher or e-commerce site.

This can mostly be explained by the poor information architecture of most think tank sites. High-value links tend to land with a thud. That is, the “authority” from those links isn’t passed along to other pages as most pages lack in-text links and have few other internal linking mechanisms.
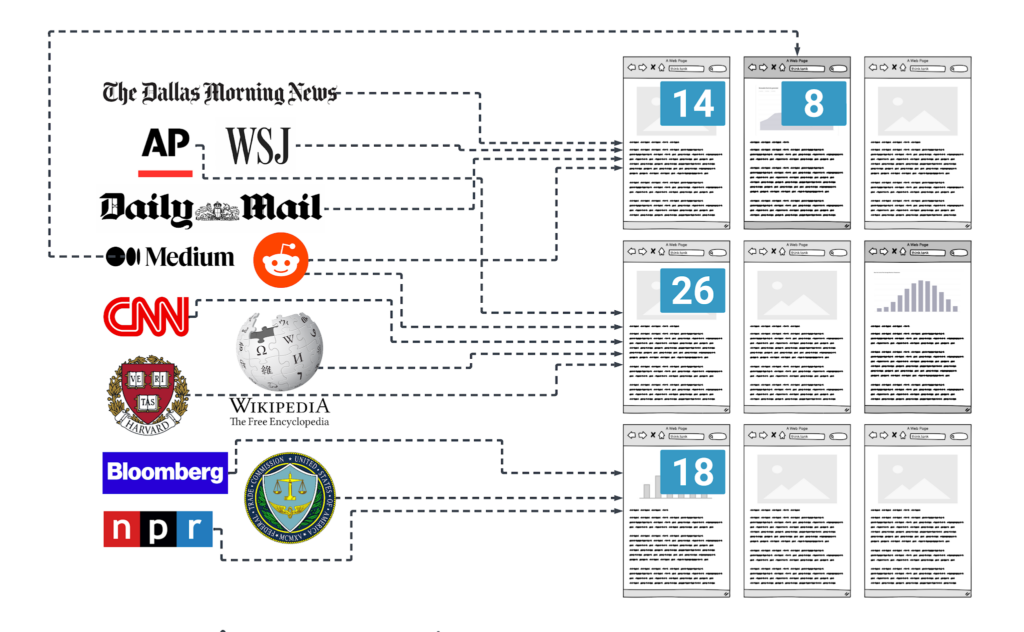
You can attempt to solve this by creating more in-text internal links. In some cases, like definitions for for terms like “alternative minimum tax” or “Section 230,” it makes sense for older page on your website to link to a newer page that defines a terms. Users are trained on this from years of clicking on links within Wikipedia articles that lead to yet another Wikipedia page.

However, linking from an older study or article page to a new study page doesn’t seem natural. Would old articles reference much newer articles in the real world? Not without time machines. So this sort of boosting of the new by linking from the old seems unnatural. It’s also not a strategy that scales.
Moreover, we can’t expect links from old content to do anything for us if we want to win a “Top stories” placement in search or appear on other “news surfaces” from Google. By the time Google were to re-crawl our site and see links pointing from old content to new content, the opportunity to rank highly for a new story would have passed. In fact, Google is so fanatical about displaying news in search results quickly that it pings major news site homepages once per second looking for updates.
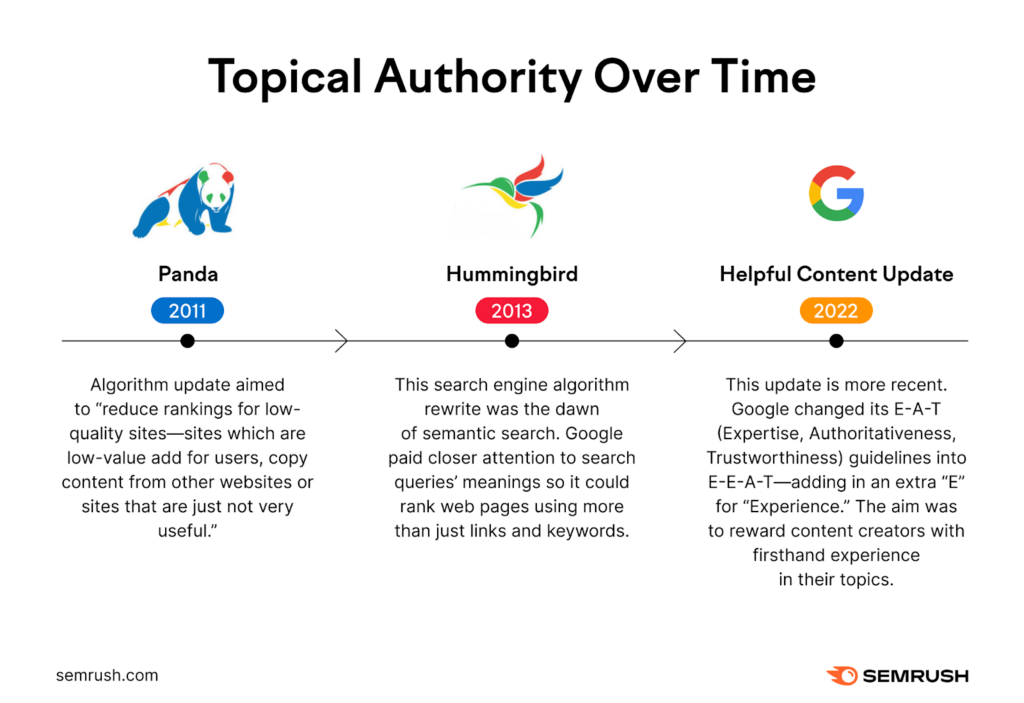
So instead of trying to raise the authority of individual pages, we need to raise the authority of topics. This concept, referred to as “topical authority” by SEOs or “topic authority” by Google itself, has been part of Google since at least the “panda” update in 2011 and has been a key part of subsequent updates like “hummingbird” and the 2023 “helpful content update.”
It’s so core to Google’s understanding of the web that the word “topic” is mentioned over 250 times in Google’s Quality Rater Guidelines, the rubric Google uses to judge its own results via an army of 10,000 search quality raters. Google places particular stress on what it calls YMYL, or “Your Money, Your Life” topics, which include “issues of public interest” and topics that could negatively impact “trust in public institutions.”
News guidelines for topic authority stress that “topic areas, such as health, politics, or finance” are subject to Google’s system that determines the expertise of sources.
So it’s inescapable for think tanks: to do well in Google Search, they must stress their Topical Authority.
This means going well beyond the Barnes-and-Noble-style broad categorical labels that so many think tanks display in their main menus. Instead, topics need to be incredible specific, tagging every person, place, organization, statute, administrative rule, legal concept, or Supreme Court decision.

Achieving this at scale requires automation. The Washington Post, when not safeguarding democracy from darkness, uses natural language processing to achieve exactly this sort of exhaustive tagging.
This creates a site architecture where every older piece on a given topic links to a topic hub. That topic hub, in turn, links to every new piece that mentions that topic. This allow link equity to naturally flow from older pieces to new pieces.
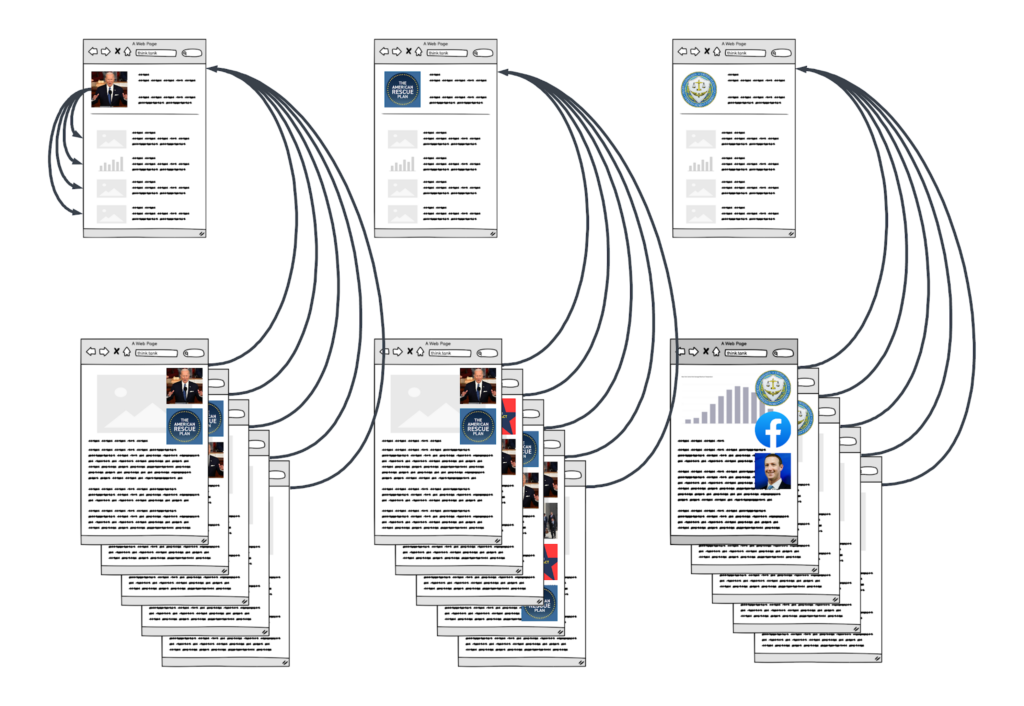
This also allows Google to judge news stories not by the links pointing to them, but by the topic under which they fall. If an outlet has written about a given topic hundreds or thousands of times, it stands to reason that they just might nail this latest story, so Google tends to reward “Top stories” positions to these known quantities.
But The Washington Post does all this using arbitrary “WashPost lexicons” rather than referring to some more universal standard for what constitutes a topic and how to label that topic. Melvil Dewey would not approve.
Rather than rolling our own classification system, it makes much more sense to defer to something centralized—something like the Library of Congress Classification (LCC) or a Dewey Decimal system for the Internet age. Thankfully, Google has created such a categorization system, a multi-dimensional mapping of all human understanding modestly titled the Knowledge Graph.
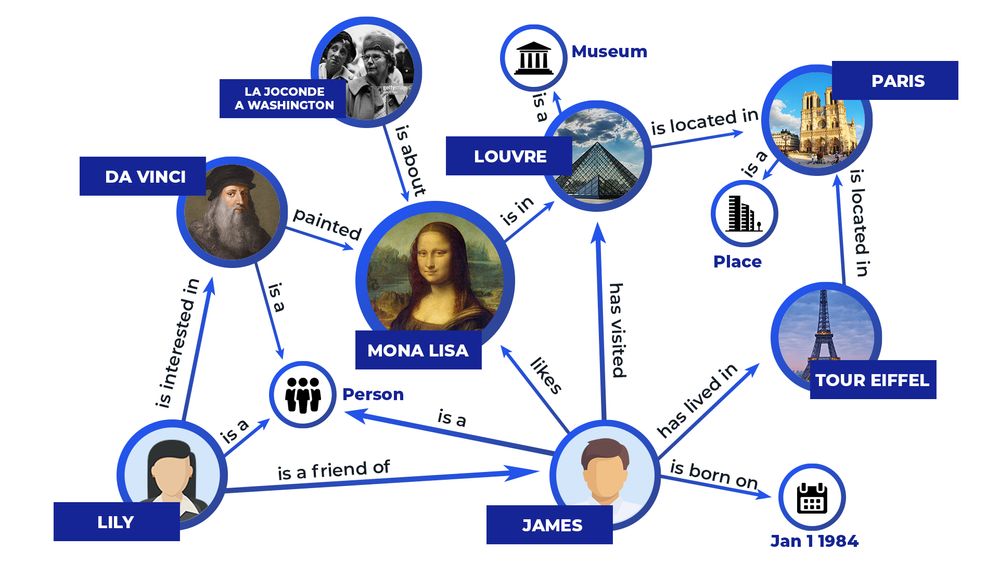
A knowledge graph is model used to store and operate on data consisting of “nodes” and “edges.” Each node is a thing/noun while each edge is a relationship, usually expressed as a verb phrase. This allows machines to gain a sort of semantic understanding. Google uses the line “things, not strings” to differentiate between how search now understands real “things” rather than merely matching specific “strings” of text.
In the context of public policy, this means that articles on a think tanks website can be connected to Knowledge Graph concepts even if those concepts don’t appear in the text of a page. For example, in discussing Biden v. Nebraska, an article needn’t mention “the major questions doctrine” or “Amy Coney Barrett” in order to appear in results for queries containing those keywords because the Knowledge Graph understands how both of those things are connected to the court’s decision.
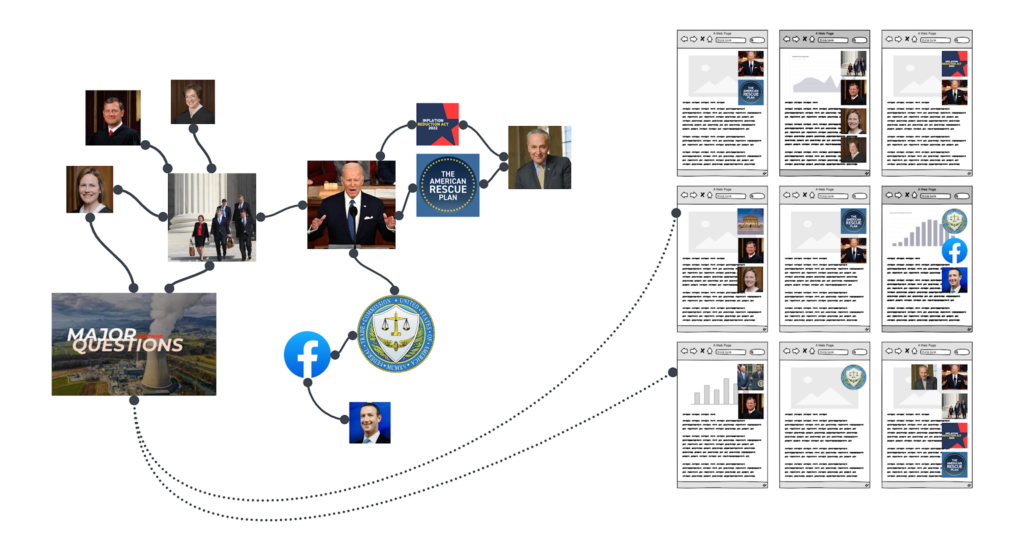
This means that a search for “biden major questions” no longer brings up a result about really big questions for the president, but rather results about the specific legal doctrine attached to a case with Biden’s name on it.
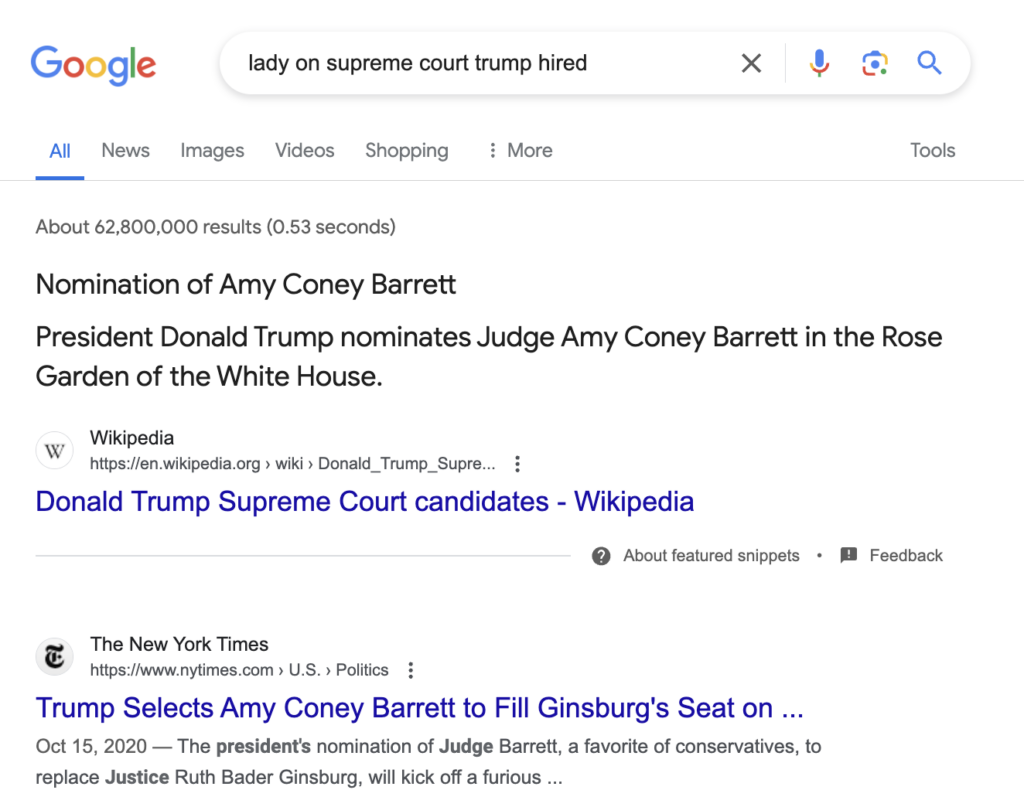
Google can even understand ineloquent queries like “lady on supreme court Trump hired” because it understands that Justice Barrett is female and that she was appointed to the Supreme Court by President Trump.
Using our own TTd Topics software, which combines Google’s NLP and Knowledge Graph APIs with other data sources, we’ve organized commentary and events at The Federalist Society around Supreme Court cases.
This has moved fedsoc.org from ranking nowhere in the top-100 for any of the cases on our initial list, to ranking in the top-10 results for over 350 case names and related terms, often outperforming sites like supremecourt.gov, harvardlawreview.org, americanbar.org, and yalelawjournal.org.
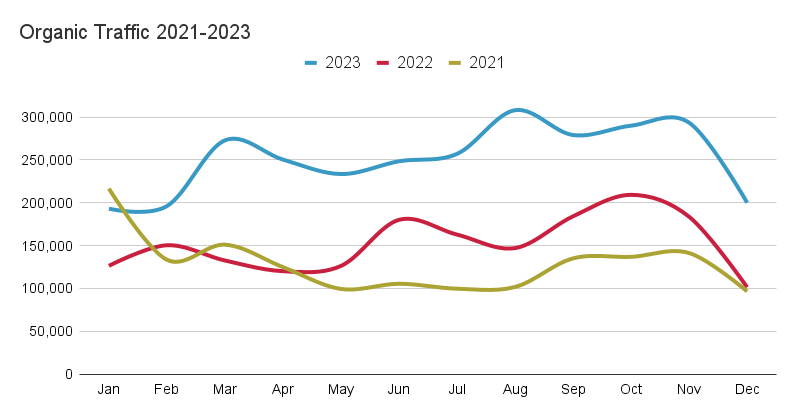
Overall this has nearly doubled views from organic search traffic for fedsoc.org over the course of two years.
To review, think tanks have two of the key ingredients for performing well in search—original content and high-quality links—but the authority from those links is often trapped in pages that don’t pass that authority along. To remedy this, you could try linking to individual pages, but that’s unsustainable, can feel unnatural, and doesn’t work for news, which drives a lot of traffic.
A better approach is to clarify authority around topics. This can be done by linking pages to topic hubs, a process that can be automated and done at scale through Natural Language Processing (NLP). Those topics should be drawn from the Knowledge Graph, Google’s interconnected web of things. By tagging your content with entities from the Knowledge Graph, you’ll increase Google’s understanding of your content, widening the number of search terms that are likely to fit your content.
If you’re interested in trying out our TTd Topics plugin and API on your website, please grab a time on Cord Blomquist’s calendar to discuss details.