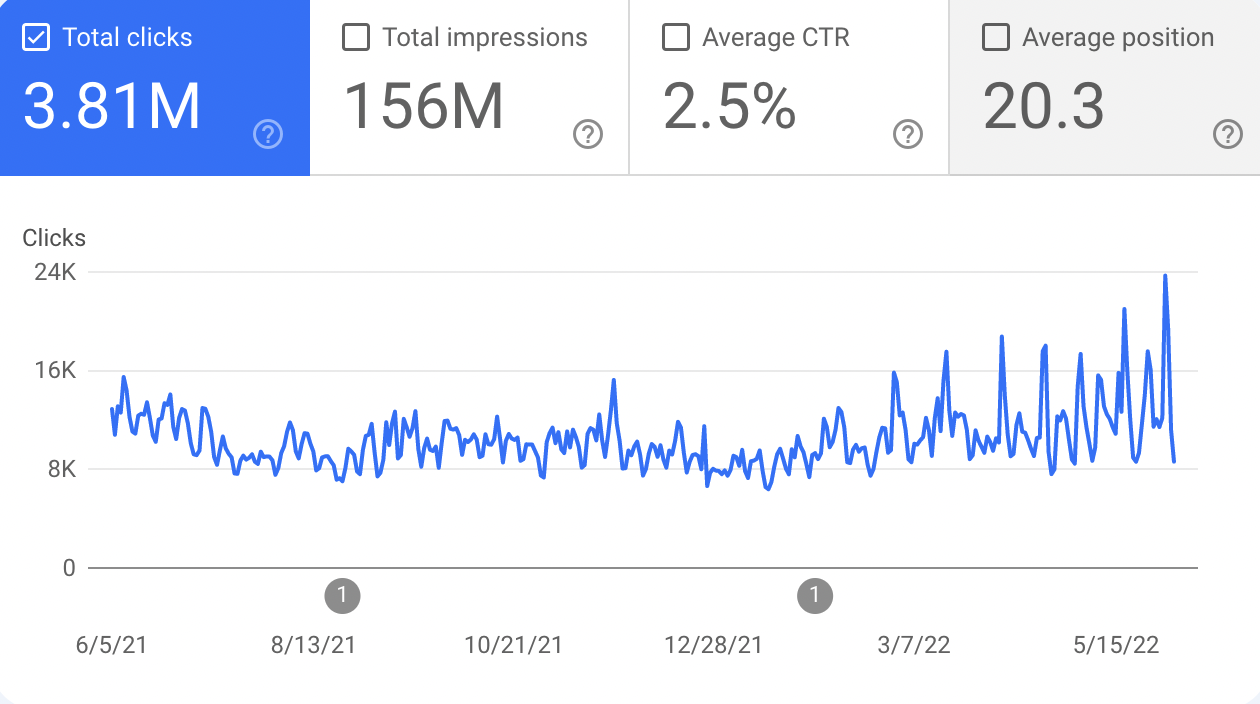
We’ve been working with a great client on regaining search traffic that started declining after Google’s June 2021 Core Update. Over the last several months, we’ve seen traffic start to rebound thanks to a great partnership with a client who’s been actively engaged in the SEO process from day one.
At the time of publishing this post, search traffic has increased 30% over the previous 3-month period. That’s over a quarter of a million more search clicks—and we’ve hit a new single-day search traffic record for the year.
Making this happen took contributions from our client’s management team, web development, and daily editing staff and we couldn’t be more pleased with how the project is progressing.
So I thought I’d share with you how we’ve achieved this result, which is just the first step in a larger SEO strategy.
Drastically Reducing the Number of URLs
Whenever we start the process of auditing a website and developing an SEO strategy, we crawl the website using a tool called Sitebulb. This not only finds a bunch of technical fixes to correct, but it also gives us a sense of the size and structure of the site—things like word count per page, the total number of pages, or the number of internal links provide us with a sense of how the site is organized.
When we tried to crawl this site, however, Sitebulb hit its limit of 2 million URLs before it could finish. This wasn’t surprising as we knew the client had something like 200,000 posts and we knew that each had multiple versions.
Modern content management systems like WordPress are really good at generating URLs. For example, the same blog post can have a root URL, mobile URL, and print URL like these:
https://example.com/2022/06/06/post-name/
https://example.com/2022/06/06/post-name/?amp
https://example.com/2022/06/06/post-name/printer
So we asked our client’s development team to give us access to Google Search Console so we could see how many URLs Google counted when it crawled the site.
The answer was a staggering 34 million URLs!
That meant that WordPress was generating 170 URLs per post. That’s way too many even for a CMS known for generating a lot of URLs.
Trying to make sense of this mountain of duplicate and superfluous content had to be confusing, even for Google’s smart algorithms.
We quickly discovered the root of the problem: our client has a really active comment section with over 8 million comments, each generating its own desktop and mobile URLs, like this:
https://example.com/2022/06/06/post-name/?comments=true#comment-9529122
And this:
https://example.com/2022/06/06/post-name/?comments=true&#comment-9529122
That’s an additional 16 million URLs added to the site!
That left another 18 million URLs unexplained, but when approaching projects like this we’ve found that you don’t need to account for every detail as common problems usually have a common fix.
That fix was actually quite simple. By declaring a page to be canonical—the one true version of the page—we can make it clear to Google that its doppelgängers ought to be ignored. Essentially, this collapses all those variations into one page in Google’s index.
That canonical tag looks like this:
<link rel="canonical" href="https://example.com/2022/06/06/post-name/">Moving Comments to a Dedicated Page
We also thought that Google shouldn’t be crawling comments in the first place. Even when comments are thoughtful and bring value to other readers, they aren’t our client’s content, so we didn’t want Google to crawl and index them as though they were. Usually, Google is pretty good about separating post content from user-generated content (UGC), but we didn’t want to take any chances.
We achieved this by moving the comments view to its own URL:
https://example.com/2022/06/06/post-title/?comments=true#comments
We then set the “Show Comments” button that moves you to that page as “nofollow,” which means that Google will not follow that link and crawl the comments.
More Content Pruning
We then reduced the site’s content even further. Again, working with a great development team really helped. Using some SQL magic and the SEO plugin, our client’s in-house development team marked over 37,000 posts as “noindex” because they were really short (under 200 words) and are considered “thin content” that Google typically doesn’t promote unless its something that you’d expect to be short, like a dictionary definition.
In fact, many of these pages weren’t getting indexed anyway, so we thought we might as well acknowledge that and let Google know they didn’t need to keep checking these URLs.
A Reduced URL Footprint
As a result of these changes, the number of URLs crawled by Google dropped from 34 million to just under 4 million—nullifying the 16 million comment URLs and most of the other unexplained cruft.
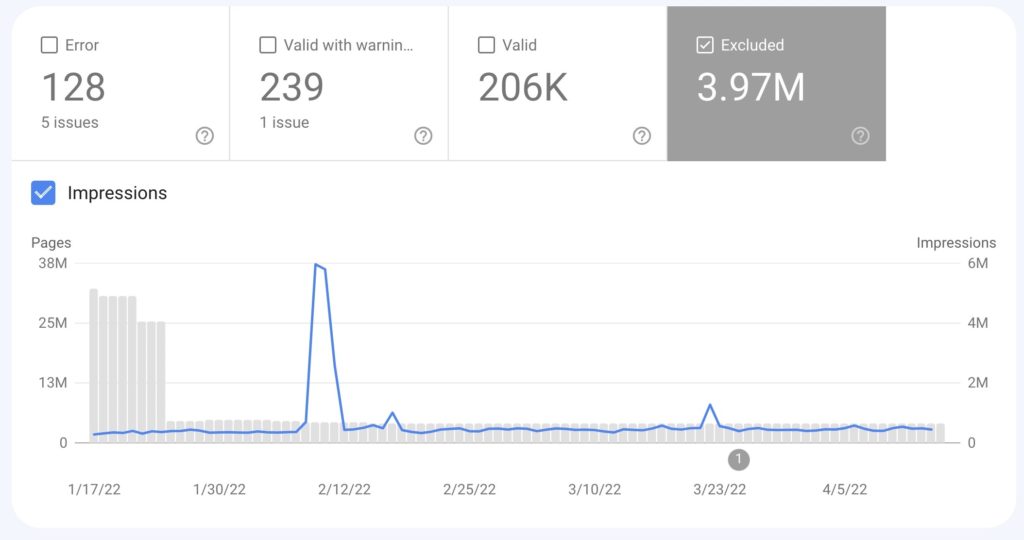
This has all resulted in a much smaller site, now with only about 150,000 URLs in the sitemap, most of those being valid and indexed.
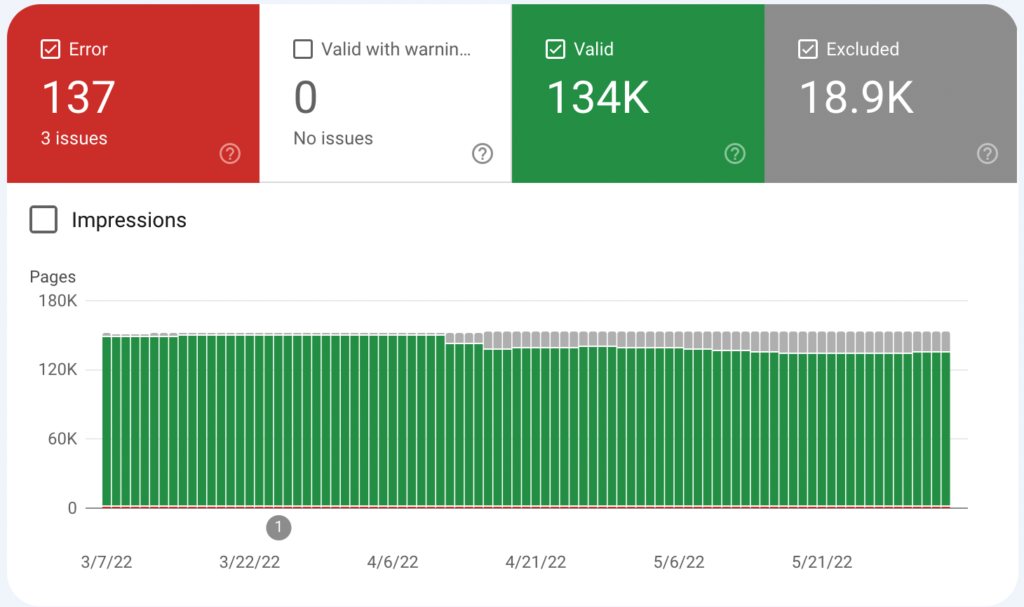
There’s still cleanup to do here, but SEO is all about making things better, not necessarily perfect.
By reducing the number of URLs, Google can now find new content faster. By reducing the URL noise, Google can more clearly see how the site is structured and how its posts and topics connect without having to sift through the auto-generated URLs.
And that’s not just theoretical, after making these canonical and “nofollow” changes, crawl rates shot up and about a month later search traffic started to creep upward.
Cutting Word Count by 75%
By making the changes above, we not only removed URLs but also reduced the total number of words Google needs to process. The total word count fell from 471 million words to 111 million words.
Again, Google is pretty good at separating main body text from other elements like menus, related posts, footers, and even comments, but by reducing the text on the page we made Google’s job much easier.
And that’s a good thing—as a rule, it’s always good to make your site’s content easier to crawl and parse, as it will help Google more accurately index your content and improve your rankings across all keywords.
More Meaningful Internal Links
Our canonical and “nofollow” changes also reduced the number of internal links from 25 million to 17 million.
Normally, an SEO project is seeking to increase the number of internal links to create content hubs or clusters, but not here.
Instead, our working theory here is that by reducing the number of internal links we’re making the site’s overall structure easier to understand—it’s no longer full of posts essentially linking to themselves.
Redirects
This site has been redesigned and rebuilt several times over the last 20 years and URL structures changed with each rebuild. This means that valuable links from high-value sites like Wikipedia, The New York Times, The Guardian, BBC, and The Washington Post were broken and getting redirected to a 404 page.
This is bad for two reasons:
- Google uses links pointing to your content as a ranking factor. If those links are pointing to a 404 page, rather than an article, that article won’t rank.
- Reference sites like Wikipedia and older posts from popular news outlets get enormous amounts of traffic, so losing those links loses referral traffic.
So, we worked with the client’s development team—and an incredibly helpful third-party developer—to create redirects. Those redirects allow links to old article URLs on the site like this:
https://example.com/021506.shtml
to redirect to new the new of that article at URLs like this:
https://example.com/2006/02/15/example-post/
That third-party developer alone created nearly 30,000 redirects, mapping the addresses of articles from the old site to their new URLs in an enormous spreadsheet of data. This resurrected years and years of valuable links pointing to our client’s site, reclaiming valuable authority.
Some of those redirects have already generated thousands of visits, proving that a publisher’s back catalog can have a very long shelf life and can continue to provide value to readers after years—or even decades in this particular case.
Still, other redirects were created using regex—rules that rewrite URLs dynamically—with one of those redirecting over 400,000 visits to the site in the course of a few months. This was a massive gain in real, measurable traffic that would have otherwise been hitting that 404 page.
Technical Details
We also paid attention to the little things, like moving metadata tags to the top of the HTML document used to generate each webpage.
This ensures that Google always crawls and captures the most important details of a page quickly. This speeds up indexation in Google News and also ensures that a page’s content is captured even if code farther down the HTML document breaks the crawler’s ability to parse the page.
As a result, the crawl error rate for this site is less than 1/10th of one percent.
Results
So what’s the moral of our story? What’s the big takeaway?
SEO isn’t always grinding away at link building or rewriting h2 tags to optimize around a particular keyword—this is especially true when working with a publisher who has great content and an enormous number of high-value links pointing to their site.
Rather than trying to manipulate Google into ranking your content, you just have to make your content easier to understand.
When you do, you not only improve your rankings, you grow the number of keywords for which your site ranks. In this particular case that meant growing the number of keywords ranked in Google’s top 10 grow from 15,723 to 21,725—an increase of 38%.
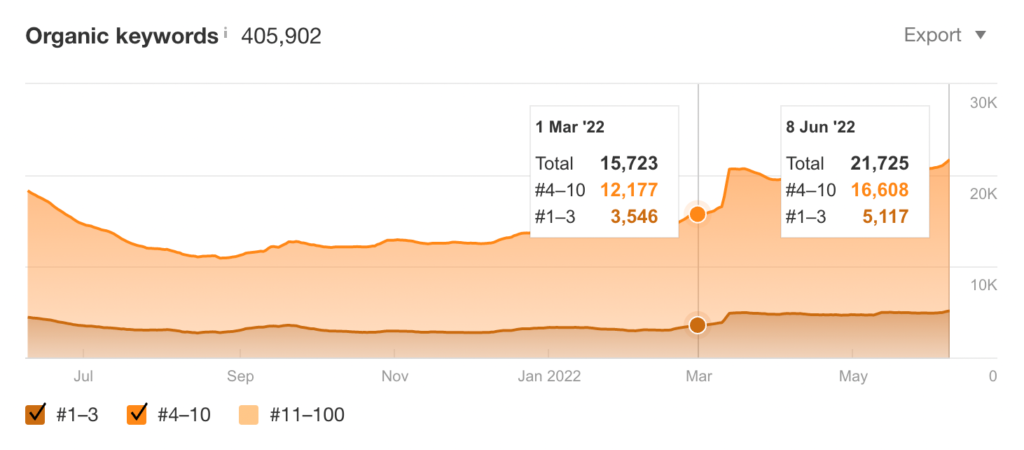
And the traffic just keeps climbing, but this is only the first step. In the coming weeks, I’ll be posting updates about how we’re addressing categorization, headline writing, E-A-T, and other website elements that affect SEO.