John Shehata published a piece at NewzDash in February that reverse-engineers Google Discover from SDK telemetry. It’s the most useful technical explanation of how Discover actually works that I’ve read. Search Engine Land extended the same model in its own coverage of how the surface qualifies, ranks, and filters content.
The pipeline Shehata describes features these 9 steps:
- Content Ingestion
- Open Graph Tag Parsing
- Content Classification
- Collection Gate
- User Interest Matching
- Ranking
- Feed Assembly
- Delivery
- Feedback Loop
As Shehata puts it: “Discover isn’t ‘one ranking algorithm’. It’s a pipeline.”
Each step reads from the one before. Get the early steps wrong, the rest don’t matter.
Shehata’s throughline: be explicit
Reading his recommendations across all nine steps you’ll find one principle runs through them: don’t rely on Google to infer meaning, declare it.
Lead with clear entities in headlines, validate Open Graph tags, ban curiosity-gap titles, and write headlines that match the underlying content. Shehata’s sharpest line: “Make topics obvious in opening sentences with clear entity names.” It’s a restatement of the oldest rule in journalism: don’t bury the lede.
Google’s own Discover documentation now backs that advice. The Feb 2026 update added a headline-content alignment classifier and explicitly says to “Use page titles and headlines that capture the essence of the content.” This isn’t an editorial theory, it’s policy.
But even if we strive to front-load relevant entities in titles and the body of an article, we’re still relying on Google to understanding meaning of the words we’re using. To use a classic SEO example, when we talk about “Georgia” we could mean the U.S. state, the country in the Caucasus, a person, a university, a typeface, or a song.
While it’s true that Google usually figures out from meaning from context, “usually” is not the same as “every time.” Ensuring that Google really does get it right every time helps us build topical authority over time.
TopicalBoost is built around this principle
TopicalBoost operationalizes declaring what you mean in two places:
- Topic identification
Every article gets tagged with a Main Topic, Also About topics, and Mentioned topics. Each tag isn’t just a string of text—it’s an object with asameAsconnection to a Google Knowledge Graph entry and, where one exists, a Wikidata URL. This ships as part of the larger JSON-LD structure created by Yoast or RankMath. This explicit entity declaration means Google no longer has infer meaning and it will come to trust your declarations when they are used honestly and judiciously over time. - Topic-led titles
Shehata says its best if “the entity is named in the headline.” We built TopicalBoost to generate a headline for search using the<title>tag and a headline for social using theog:titletag. Both incorporate what we call the “focus topic” of the article, which occupies themainEntityspot in the JSON markup. This means that by default our plugin places the entity in the headline. In fact, it generates 5 SEO headlines and 5 social headlines, all containing the focus topic, and allows the user to pick from them.
While we’re on the subject of what gets handed to the pipeline by default, TopicalBoost also generates 16:9, 4:3, and 1:1 versions of the WordPress Featured Image automatically. That’s exactly the set Google recommends for Discover — multiple aspect ratios, minimum 1200 pixels wide. The aspect ratios aren’t about topics, but they’re another thing we don’t leave to chance. Step 2 (Open Graph Tag Parsing) gets the right ratio for whichever surface is rendering the card, and Step 6 (Ranking) reads richer image signals when the right size is available.
Both pillars (and the image variants alongside them) move work that was happening implicitly, or not at all, into the editorial workflow itself.
What this looks like at scale
When we compared six months of running TopicalBoost at Illinois Policy to the previous six months, the Discover numbers moved dramatically. Monthly Google Discover clicks roughly tripled — from about 62,000 to about 166,000. Peak month topped 250,000. Site-wide organic traffic grew with it.
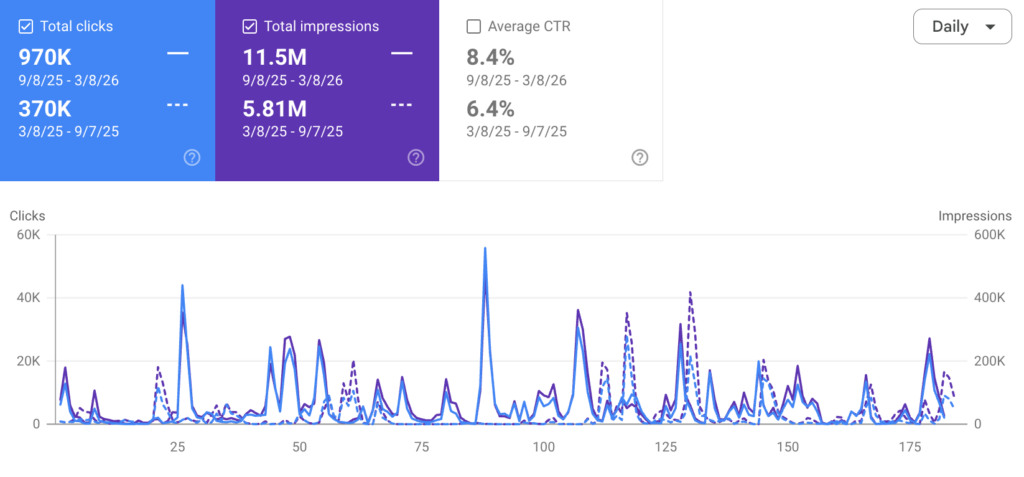
The more telling number than total volume is breadth. In the earlier six months, 39 distinct articles each pulled at least 1,000 Discover clicks. In the more recent six months, more than 80 did. The growth wasn’t a small set of viral hits; fresh entity-tagged content kept getting matched to entity-interested readers across a wider slice of the archive.
That breadth is the fingerprint of better audience matching. Every article ships with declared entities, and those entities are connected to topic hubs through internal links shaped by the Knowledge Graph. Google has clean signal about what each piece is about and which readers it should reach.
Trace the pipeline backwards from there:
- Step 8 (Delivery) runs cleanly because the entities and topic hubs are explicit. Discover sends the article to the right audience the first time. Engagement holds up. The spike-and-drop pattern that Google’s Feb 2026 alignment classifier was designed to catch gets harder to trigger when the title and the content describe the same thing.
- Step 9 (Feedback Loop) observes that engagement and learns from it.
- Step 4 (Collection Gate) opens wider over time, because Step 9’s record of clean engagement is what earns publisher-level eligibility for more impressions, more entities, and broader page mixes.
Delivery drives the results. The feedback loop sees the results. The collection gate opens because of the results. The pipeline compounds.
The same flywheel is documented in our Illinois Policy case study under “The Compounding Pattern.”
Don’t leave it to chance
Shehata gives publishers a clean map of the pipeline. The lever, across most of it, is the same. Be explicit about topics. Declare those topics in the surfaces Google parses — headlines, Open Graph tags, schema. Hand the pipeline the image sizes it expects, too. Don’t leave any of it to chance.
The Feb 2026 Discover update tilts Google Discover toward topic-specialized publishers and away from clickbait. Publishers who do the work of being explicit will get a boost at every step in the process: the headline classifier reads them favorably, the matching step finds the right audience, and the feedback loop compounds the result.
That’s the work TopicalBoost handles by default, post by post, across your entire site.
