Search “Georgia.” Google has to decide whether you mean the U.S. state, the country in the Caucasus, the Atlanta sports city, the typeface, or the song. It almost always gets it right. The reason it gets it right is the Knowledge Graph, a database of distinct things rather than strings of letters. As Google’s Chuck Rosenberg explained when introducing entity-based image search in 2013, “an entity is a way to identify something in a language-independent way uniquely.”
For most search queries, that disambiguation is invisible work. For publishers, it isn’t. A think tank covering Georgia (the state) and a magazine covering Georgia (the country) are competing for the same headline word but for completely different concepts. The Knowledge Graph is what Google uses to tell them apart and, increasingly, to decide which one to rank for what.
If you’ve ever wondered why we keep talking about “entities” instead of “keywords,” or why TopicalBoost makes such a fuss about declaring topics explicitly, the Knowledge Graph is the answer.
What the Knowledge Graph actually is
Google launched the Knowledge Graph on May 16, 2012. At launch, the Knowledge Graph contained roughly 500 million entities and 3.5 billion facts about them. As of 2020, the count was 500 billion facts about five billion entities. Most of Google’s surfaces—Search, Discover, News, Top Stories, AI Overviews, and the Knowledge Panels you see on the right side of the SERP—read from it.
What’s in there? Well, everything:
- people
- organizations
- places
- products
- events
- books
- films
- ideas
- concepts
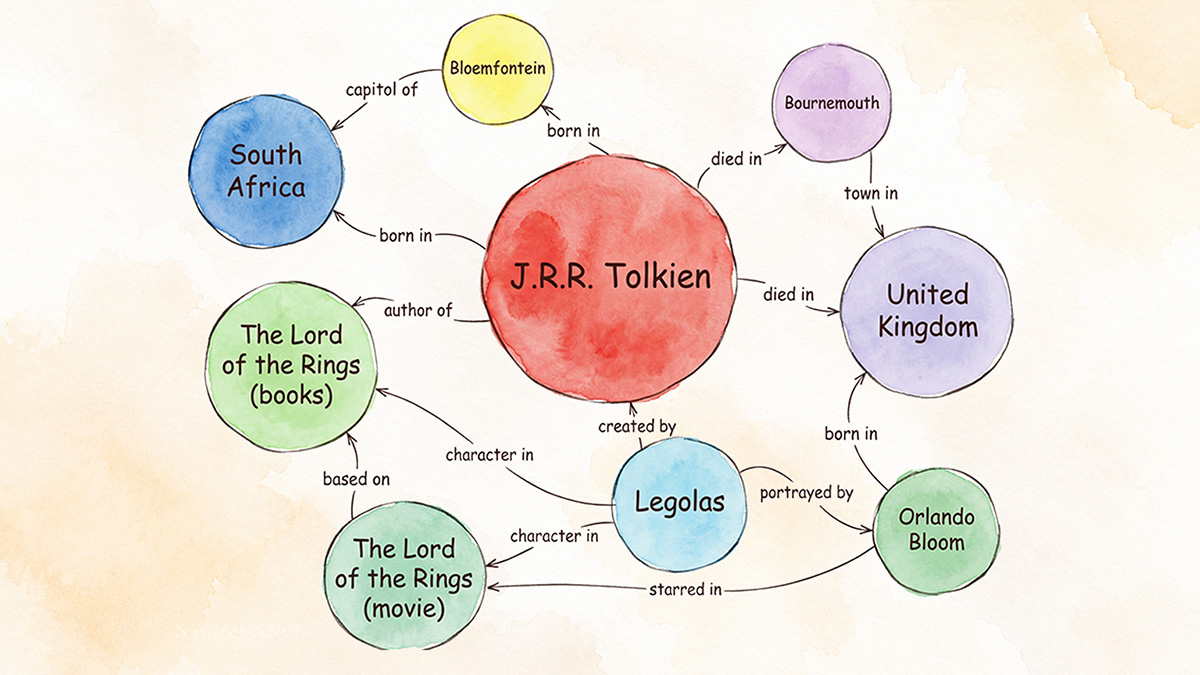
Each entity has a stable identifier independent of language or spelling. The Marco Rubio entity is the same object whether you’ve written about him as “Senator Rubio,” “Secretary Rubio,” “Marco Antonio Rubio,” or in Spanish-language coverage.
But the database isn’t just a list. The “graph” part of “Knowledge Graph” is the relationships between entities. Marco Rubio is connected to “U.S. Secretary of State” through a holds position relationship. “Secretary of State” is connected to “U.S. Cabinet” through a part of relationship. “U.S. Cabinet” is connected to “executive branch,” and so on. Google doesn’t just know what each entity is, it knows how they relate.

That structure is what makes the insightful connections between entities Bill Slawski wrote about possible. Google can surface relationships you didn’t ask about but are glad to see.
Where it came from
The Knowledge Graph didn’t emerge from nothing. Its foundation came from Google’s 2010 acquisition of Metaweb, the company behind Freebase, a community-built database of “things” with stable identifiers and structured relationships. When Google announced the Knowledge Graph in 2012, the launch tagline was things, not strings.

That phrase is the entire conceptual shift. Pre-2012 Google ranked documents by matching keyword strings. Post-2012 Google increasingly ranks documents by understanding which things each document is about and which other things those things are connected to.
Andrea Volpini at WordLift has written extensively about how this changed the practitioner side of SEO. Content stopped being a collection of pages with the right keywords in them and started being linked data with relationships Google could read directly.
How Google actually uses it
The Knowledge Graph in 2026 is not a novelty bolted onto search results. It’s load-bearing across the modern Google stack, and the evidence for that has gotten less speculative over the last two years.
Mike King’s analysis of the 2024 Google Content Warehouse leak made the connection concrete. The leaked documentation references a “topicality score”—a measure of how connected the entities in a document are—used as a relative ranking signal between competing pages on the same entity. The same documentation revealed that mentions of an entity reinforce that entity even without links. As King put it, “mentions are not treated as links, but mentions are reinforcing the entities.” That single line captures the shift. Google is evaluating documents by what they’re about at the entity level, not just by which words and links appear.
Olaf Kopp’s deep dive in Search Engine Land goes further. Kopp frames entities as “the central organizational element in semantic databases, such as Google’s Knowledge Graph,” and traces how AI Overviews, Knowledge Panels, and conversational search all read from structured knowledge rather than keyword signals. If your brand or your topic isn’t recognized as an entity in that structure, you struggle to appear in the high-visibility surfaces, even if you rank well in classical keyword search.
Lily Ray has argued for years that Google evaluates expertise, authoritativeness, and trustworthiness at the entity level. If Google has enough understanding of you (an author) or your publication (an organization), you’re treated as an entity, and that recognition determines whether you surface in the carousels that the unrecognized never enter. Ray’s line on the topic stands:
any SEO who hasn’t jumped onto the E-E-A-T wave isn’t paying close attention to what Google has been building.
All of these brilliant SEOs are driving home the same point. Entities aren’t how Google “decorates” a search result. They’re how Google decides what a search result is.
What this means for publishers
Most posts about the Knowledge Graph are written for brands trying to get themselves into a Knowledge Panel. But that isn’t “the publisher problem.”
The publisher problem is different. You have an archive—hundreds or thousands of articles, written over years, about a recurring set of subjects. Some of those subjects are entities Google already knows perfectly well: Marco Rubio, the Federal Reserve, the U.S. Senate. Some are local or specialized entities Google has only fuzzy data on, like your state legislators, niche organizations, and specific bills. Some are conceptual entities like zero-based budgeting, civil asset forfeiture, or occupational licensing, where Google needs help understanding what the article is even about.
Three things follow from that.
Disambiguation compounds. Every article that explicitly declares which “Georgia” or which “Jefferson” it’s about strengthens Google’s confidence in your archive’s coverage of that entity. Articles that don’t declare their entities leave Google to infer them from context. Inference works most of the time. But doesn’t work every time. Across an archive of thousands of articles, “most of the time” is a slow leak.
Topical authority routes through entities, not abstractions. Publishers don’t rank for “topics” as a concept. They rank for the entities that constitute a topic. Coverage of immigration policy is really coverage of dozens of specific entities—bills, agencies, court cases, people, programs—that Google can recognize and connect. The publisher who covers thirty entities deeply ranks better on the topic than the publisher who covers three entities deeply and the rest implicitly.
Discover, News, and Top Stories are entity-driven surfaces. As Lily Ray’s Discover work has documented, the carousels Google assembles aren’t “best articles about a query.” There is no query. They’re best articles about an entity, matched to a user with prior interest in that entity. Publishers whose archives can’t be parsed entity-by-entity don’t enter those carousels.
Declare, don’t infer
The single principle that runs through everything above: stop letting Google guess; declare. We’ve written about why this matters at the article level in the context of John Shehata’s reverse-engineering of the Google Discover pipeline.
The mechanism isn’t complicated or mysterious. Schema.org structured data with sameAs references that point each entity in your article to its identifier in Google’s Knowledge Graph and, where one exists, its Wikidata URI. That’s how a publisher tells Google in machine-readable terms: this article is about this specific Marco Rubio, who is connected to these other entities, and is part of this larger topic. As Volpini frames it, the work is “turning information into linked data.” The information was always there, the structured-data layer simply makes it machine-readable.
This is what TopicalBoost does, by default, in the WordPress editor. Every article ships with JSON-LD that names exactly which entities the piece is about.
The takeaway
Publishers who think in keywords are competing with everyone who can string the same words together. Publishers who think in entities are competing on what they actually own: deep, recurring, authoritative coverage of a specific set of things.
The Knowledge Graph is the structure that allows that ownership to get recognized. Make Google’s job easy. Declare what you cover. The compounding is on the other side.
